
Attention is all you need is a paper written by Vaswani, Ashish & Shazeer, Noam & Parmar, Niki & Uszkoreit, Jakob & Jones, Llion & Gomez, Aidan & Kaiser, Lukasz & Polosukhin, Illia. The wonderful piece changed the world of NLP and put forward the concept of usage of attention mechanism to build wonderful Transformer models. Following this lot of work has been done and many successful models in NLP are using attention networks.
The core concept of Attention mechanism is in preserving contextual information around a word. Whereas lot of work has been done on Attention network in NLP however, in computer vision, convolutional neural networks (CNNs) are still the norm and self-attention just began to slowly creep into the main body of research, either complementing existing CNN architectures or completely replacing them.
Empirically speaking Attention Network in computer vision aims to emulate human visual perception. Often we spot something catchy in room and our eye is able to focus on particular object clearly ignoring other objects in room. When we must focus on a single object , the attention mechanism within our visual perception system uses a sophisticated group of filters to create a blurring effect so the object of interest is in focus, while the surrounding is faded or blurred.
In one of our project at EulersLab we added attention network in top of Vgg16 and results were amazing.

Attention networks can also be added at various stages of CNN layers to focus on images at different levels
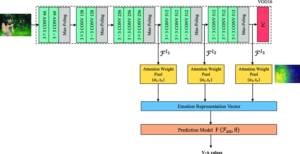
The concept of Attention in Computer Vision was introduced in the 2016 paper titled "SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning". SCA-CNN demonstrated the potential of using multi-layered attention: Spatial Attention and Channel Attention combined, which are the two building blocks of CBAM in Image Captioning
WHY WE NEED ATTENTION IN COMPUTER VISION
For features extraction from images, numerous models based on object segmentation, semantic segmentation and instance segmentation have been built. The models like Faster_RCNN,Mask_RCNN,U-Net,YOLO have been very successfully used ,however they need lot of data preparation whereas using labeling tools we create bounding boxes around region of interest. This is painful and time consuming and need special effort .However there are cases where images have already been captioned for eg client in healthcare may have Xray pics of patients having Tuberculosis but it will be difficult for them to create a bounding box in Xray images around region of interest. That is where Attention network can come in handy.
[ht-ctc-chat]
Avesh